What Is A Speech Recognition System?
A speech recognition system is a type of software that allows the user to have their spoken words converted into written text in a computer application such as a word processor or spreadsheet. The computer can also be controlled by the use of spoken commands.
Speech recognition software can be installed on a personal computer of appropriate specification. The user speaks into a microphone (a headphone microphone is usually supplied with the product). The software generally requires an initial training and enrolment process in order to teach the software to recognise the voice of the user. A voice profile is then produced that is unique to that individual. This procedure also helps the user to learn how to ‘speak’ to a computer.
About
When you dial the telephone number of a big company, you are likely to hear the sonorous voice of a cultured lady who responds to your call with great courtesy saying “welcome to company X. Please give me the extension number you want” .You pronounce the extension number, your name, and the name of the person you want to contact. If the called person accepts the call, the connection is given quickly. This is artificial intelligence where an automatic call-handling system is used without employing any telephone operator.
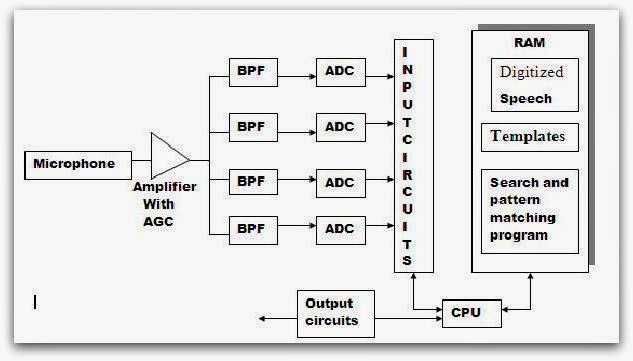
Working Of The System
The voice input to the microphone produces an analogue speech signal. An analogue to digital converter (ADC) converts this speech signal into binary words that are compatible with digital computer. The converted binary version is then stored in the system and compared with previously stored binary representation of words and phrases.
What Software Is Available?
There are a number of publishers of speech recognition software. New and improved versions are regularly produced, and older versions are often sold at greatly reduced prices. Invariably, the newest versions require the most modern computers of well above average specification. Using the software on a computer with a lower specification means that it will run very slowly and may well be impossible to use. There are two main types of speech recognition software: discrete speech and continuous speech.
Acceptance And Rejection
When the recognition engine processes an utterance, it returns a result. The result can be either of two states: acceptance or rejection. An accepted utterance is one in which the engine returns recognized text. Whatever the caller says, the speech recognition engine tries very hard to match the utterance to a word or phrase in the active grammar.
Sometimes the match may be poor because the caller said something that the application was not expecting, or the caller spoke indistinctly. In these cases, the speech engine returns the closest match, which might be incorrect. Some engines also return a confidence score along with the text to indicate the likelihood that the returned text is correct. Not all utterances that are processed by the speech engine are accepted. Acceptance or rejection is flagged by the engine with each processed utterance.
The Limits Of Speech Recognition
To improve speech recognition applications, designers must understand acoustic memory and prosody. Continued research and development should be able to improve certain speech input, output, and dialogue applications. Speech recognition and gen-eration is sometimes helpful for environments that are hands-busy, eyes-busy, mobility-required, or hostile and shows promise for telephone-based ser-vices.
Dictation input is increasingly accurate, but adoption outside the disabled-user community has been slow compared to visual interfaces. Obvious physical problems include fatigue from speaking continuously and the disruption in an office filled with people speaking.
By understanding the cognitive processes sur-rounding human “acoustic memory” and process-ing, interface designers may be able to integrate speech more effectively and guide users more suc- cessfully. By appreciating the differences between human-human interaction and human-computer interaction, designers may then be able to choose appropriate applications for human use of speech with computers.
Conclusion
Speech recognition will revolutionize the way people conduct business over the Web and will, ultimately, differentiate world-class e-businesses. VoiceXML ties speech recognition and telephony together and provides the technology with which businesses can develop and deploy voice-enabled Web solutions TODAY! These solutions can greatly expand the accessibility of Web-based self-service transactions to customers who would otherwise not have access, and, at the same time, leverage a business’ existing Web investments.
No comments:
Post a Comment